
 Im eBook-Shop gibt es Klausuraufgaben zu diesem Thema!
Im eBook-Shop gibt es Klausuraufgaben zu diesem Thema!Testen von Einflüssen
In den bisherigen Artikeln haben wir uns nur mit dem Schätzen von den Parametern der Regression beschäftigt.
Manchmal ist das schon genug, und wir sind mit dem Ergebnis zufrieden. Wenn wir z.B. das Modell einfach nur verwenden möchten, um eine Vorhersage zu erstellen, dann brauchen wir nur die Parameter, und können dann, wenn wir neue Einflussgrößen bekommen, eine Vorhersage für die Zielgröße machen.
In der Praxis ist das Schätzen von Parametern aber oft nur der erste Schritt, und der zweite Schritt ist dann das Testen dieser Parameter. Denn oft interessiert uns als zweiter Schritt, ob eine bestimmte Einflussgröße „wichtig“ für die Vorhersage der Zielgröße ist.
„Wichtig“ definieren wir hier als: Nicht 0. Denn wenn ein Parameter in Wirklichkeit 0 oder nahe an 0 ist, dann hat eine Einflussgröße keinen Effekt auf die Zielgröße, und wir könnten sie einfach wieder entfernen.
Dazu ein Beispiel: Wir möchten das Gewicht einer Person vorhersagen, mit Hilfe seiner Körpergröße (in Metern) und der Hausnummer seiner Adresse.
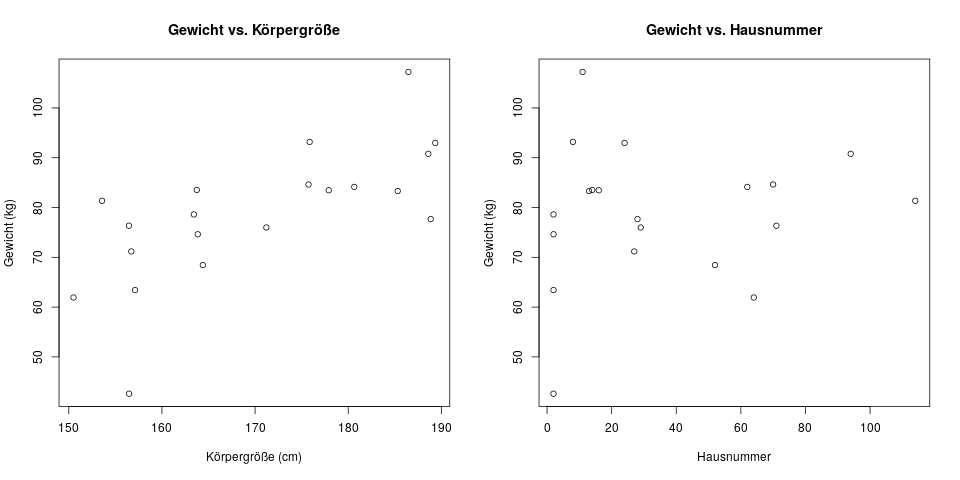 Die Grafiken zeigen, dass größere Menschen tendenziell schwerer sind, d.h. der Regressionsparameter \(b\) für die Körpergröße wird wahrscheinlich größer als Null sein. Allerdings gibt es zwischen der Hausnummer und dem Gewicht einer Person (wie erwartet) keinen wirklichen Zusammenhang. Der Vorteil ist nun, dass wir diese Variable rauswerfen können, und in zukünftigen Befragungen die Leute nicht mehr nach ihrer Adresse fragen müssen. Dadurch sparen wir Zeit und evtl. auch Geld, und der kürzere Fragebogen führt vielleicht auch zu mehr Bereitschaft zur Teilnahme, und damit einer größeren Stichprobe am Ende.
Die Grafiken zeigen, dass größere Menschen tendenziell schwerer sind, d.h. der Regressionsparameter \(b\) für die Körpergröße wird wahrscheinlich größer als Null sein. Allerdings gibt es zwischen der Hausnummer und dem Gewicht einer Person (wie erwartet) keinen wirklichen Zusammenhang. Der Vorteil ist nun, dass wir diese Variable rauswerfen können, und in zukünftigen Befragungen die Leute nicht mehr nach ihrer Adresse fragen müssen. Dadurch sparen wir Zeit und evtl. auch Geld, und der kürzere Fragebogen führt vielleicht auch zu mehr Bereitschaft zur Teilnahme, und damit einer größeren Stichprobe am Ende.
Hypothesen
Wir möchten also, wie oben beschrieben, wissen welche Einflussgrößen bzw. Parameter „wichtig“ für unser Regressionsmodell sind.
Die Hypothesen bei einer linearen Regression sind immer gleich. Für jeden berechneten Parameter, z.B. \(a\) und \(b\) bei der einfachen linearen Regression, führen wir einen Test durch, mit zwei Hypothesen. Am Beispiel für den Steigungsparameter \(b\) der Regressionsgeraden lauten sie: \(H_0\): Der Parameter \(b\) ist Null. \(H_1\): Der Parameter \(b\) ist ungleich Null.
Wenn wir diesen Test durchführen, und als Resultat die Nullhypothese ablehnen, dann können wir sagen, dass der Parameter \(b\) „signifikant ist“. Wir meinen damit ausführlich: Der Parameter \(b\) ist signifikant von Null verschieden.
Signifikanz
Das Signifikanzniveau, das wir festlegen müssen, gibt an wie sicher wir uns sein möchten, bevor wir die Nullhypothese bei einem Test ablehnen. Es ist genau dasselbe Prinzip wie bei den Hypothesentests in der Parameterschätzung. Punkt 3 in diesem Artikel erklärt dieses Prinzip bereits gut, aber es sei hier nochmal kurz zusammengefasst:
Wir nennen einen Parameter signifikant ungleich 0, wenn es „sehr unwahrscheinlich“ ist, dass der wahre Parameter 0 ist.
Wann etwas „sehr unwahrscheinlich“ ist, muss man vohrer definieren, indem man ein Signifikanzniveau \(\alpha\) festlegt. Meist ist, wie bei anderen Hypothesentests auch, \(\alpha=0.05\) ein gerne genutzter Wert. Das bedeutet sinngemäß, dass wir nur in 5% der Fälle die Nullhypothese ablehnen, obwohl sie in Wirklichkeit wahr ist. Wenn man allerdings noch sicherer sein möchte, keinen Fehler zu machen, kann man z.B. auch \(\alpha=0.01\) setzen.
Hier rechnen wir mit p-Werten
Wir erinnern uns, dass es zwei mögliche Arten gibt, die Entscheidung eines Tests zu berechnen: Entweder durch das Bestimmen eines kritischen Bereichs, oder durch das Berechnen eines p-Werts.
Detailliert wurde der Unterschied dieser beiden Wege in diesem Artikel bereits erklärt. Aber zusammenfassend sei nochmal gesagt:
- Bei der Berechnung via kritischen Bereich bestimmt man eine Prüfgröße \(T\) und einen kritischen Bereich (meist ein oder zwei Intervalle). Der kritische Bereich hängt auch vom Signifikanzniveau \(\alpha\) ab. Wenn die Prüfgröße im kritischen Bereich liegt, wird die Nullhypothese abgelehnt, anderenfalls nicht.
- Bei der Berechnung via p-Wert bestimmt man nur eine Zahl, den p-Wert. Wenn dieser kleiner ist als das vorgegebene Signifikanzniveau \(\alpha\), dann wird die Nullhypothese abgelehnt, anderenfalls nicht.
Hier sieht man auch einen weiteren Vorteil an der Variante via p-Wert: Man sieht sofort, zu welchem Signifikanzniveau dieser Test die Nullhypothese ablehen würde. Wenn der p-Wert also zum Beispiel p=0.0832 ist, dann würden wir direkt sehen, dass man zum Niveau \(\alpha=0.05\) die Nullhypothese nicht ablehnen würde, aber zum Niveau \(\alpha=0.1\) schon – denn 0.0832 ist kleiner als 0.1. Würde man stattdessen mit dem kritischen Bereich rechnen, bekäme man am Anfang nur die Information: „Zum Niveau \(\alpha=0.05\) ist der Test nicht signifikant“. Man müsste ihn dann zum Niveau \(\alpha=0.1\) nocheinmal von vorne rechnen.
Im Kapitel zu Hypothesentests bei Vereteilungsparametern haben wir noch viel mit kritischen Bereichen gerechnet, da diese Variante gut mit der Hand zu berechnen ist, und sie daher in Klausuren immer noch abgefragt wird. In der Realität, und besonders bei komplexeren Hypothesentests, wird die Testentscheidung allerdings fast ausschließlich mit p-Werten berechnet. Das Ergebnis (der p-Wert) ist einfacher zu interpretieren, und gibt etwas detailliertere Informationen zurück als die sture „ja“/“nein“-Entscheidung, wenn man den Weg über den kritischen Bereich geht.
Ein p-Wert ist ein bisschen schwerer von Hand zu berechnen, aber wir gehen hier davon aus, dass wir in einer Klausur oder Übungsaufgabe nie einen p-Wert von Hand berechnen müssen. Oftmals ist in einer Klausur zum Beispiel eine „fertige“ Regression abgedruckt, und man muss die Ergebnisse in eigenen Worten interpretieren können.
Hier ist nochmal das Bild mit den Daten von oben, aber diesmal mit Regressionsgeraden eingezeichnet.
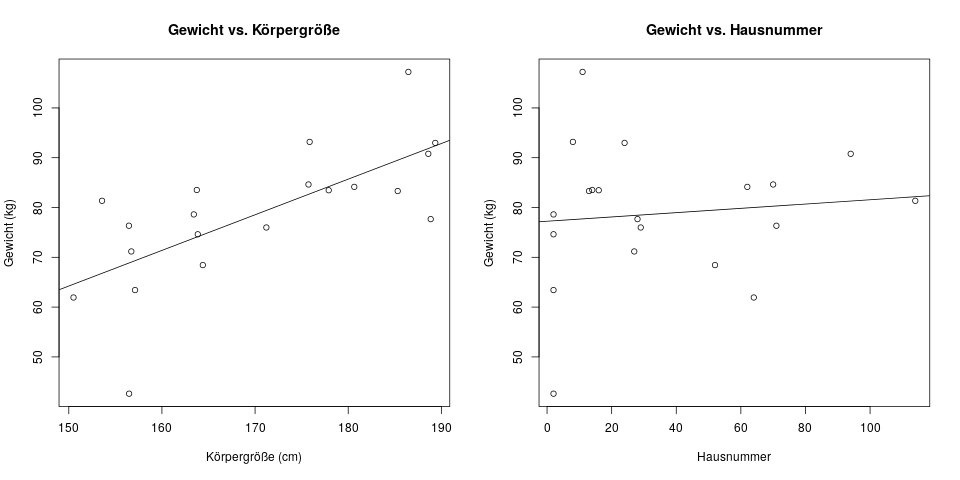 Für den Zusammenhang zwischen Körpergröße und Gewicht sieht man eine klare positive Steigung. Für die Hausnummer sieht man zwar eine ganz leicht steigende Gerade, die allerdings nicht signifikant ist – das sehen wir an der Ausgabe der Regression:
Für den Zusammenhang zwischen Körpergröße und Gewicht sieht man eine klare positive Steigung. Für die Hausnummer sieht man zwar eine ganz leicht steigende Gerade, die allerdings nicht signifikant ist – das sehen wir an der Ausgabe der Regression:
| Schätzer | Standardfehler | t-Statistik | p-Wert | |
|---|---|---|---|---|
| Intercept \(a\) | -48.012 | 30.144 | -1.593 | 0.130 |
| Größe \(b_1\) | 0.730 | 0.175 | 4.181 | 0.001 |
| Hausnummer \(b_2\) | 0.068 | 0.069 | 0.985 | 0.339 |
Jedes Statistikprogramm gibt das Ergebnis etwas anders aus, aber die wichtigsten Zeilen sind die für den Schätzer, und die für den p-Wert. An dieser Ausgabe kann man die folgenden Dinge ablesen:
- In der Spalte Schätzer sieht man: die Regressionsgerade lautet: \(y = -48.012 + 0.730\cdot x_1 + 0.068\cdot x_2\), wobei \(x_1\) die Körpergröße in cm ist, und \(x_2\) die Hausnummer einer Person.
- Der Parameter \(b_1\) ist 0.730. Das heißt also, dass eine Person die 1cm größer ist, im Durchschnitt geschätzt 0.730kg, also 730 Gramm mehr wiegt.
- Der Parameter \(b_2\) ist 0.068. Das heißt also, dass eine Person deren Hausnummer um 1 höher ist, etwa 0.068kg, also 68 Gramm mehr wiegt. Ob dieser Zusammenhang aber auch tatsächlich da ist, also statistisch signifikant ist, werden wir gleich sehen.
- Die Spalten Standardfehler sowie t-Statistik sind Zwischenergebnisse, die man zum Berechnen des p-Werts in der letzten Spalte benötigt. Manche Statistikprogramme geben diese Werte auch gar nicht aus. Meist kann man die ignorieren, da man nur am p-Wert interessiert ist.
- Der p-Wert für jeden Parameter liefert uns nun die Information, ob ein Parameter „wichtig“ oder nicht ist, d.h. ob er signifikant ist.
- Der p-Wert für den Intercept wird normalerweise auch ignoriert, da er keine Aussage über einen Parameter trifft. Meistens beachtet man ihn nicht.
- Der p-Wert für die Körpergröße, also für den Parameter \(b_1\), ist hier 0.001. Das ist weit kleiner als das Signifikanzniveau \(\alpha=0.05\), daher ist dieser Parameter signifikant. Wir können also sagen, dass die Körpergröße einen signifikanten Einfluss auf das Gewicht einer Person hat.
- Der p-Wert für die Hausnummer einer Person, also für den Parameter \(b_2\), ist 0.339. Das ist recht groß, insbesondere größer als das Signifikanzniveau von 0.05. Die Hausnummer einer Person hat also keinen signifikanten Einfluss auf ihr Gewicht.
Obwohl der Parameter für die Hausnummer einer Person nicht signifikant ist, wird er natürlich durch den Zufall bedingt niemals als genau 0 geschätzt. Es kommt immer eine gewisse Zahl dabei heraus, und die Interpretation klingt in diesem Fall tatsächlich etwas komisch: eine Person, deren Hausnummer um 1 höher ist, wiegt etwa 68 Gramm mehr.
Einseitige vs. zweiseitige Tests
Wie bei Hypothesentests für Verteilungsparameter, können wir uns auch hier für einseitige oder zweiseitige Tests entscheiden. Der Unterschied ist in diesem Artikel gut erklärt, aber nochmal kurz die Zusammenfassung:
Ein einseitiger Test hat den Vorteil dass er bei geringer Stichprobengröße mit wenig Beweiskraft einen Effekt auch dann erkennt, wenn ein zweiseitiger Test ihn noch nicht erkennen würde. Ein zweiseitiger Test braucht immer etwas mehr Daten bzw. einen etwas eindeutigeren Zusammenhang, um diesen dann auch als signifikant zu erkennen.
Trotzdem verwendet man eigentlich immer zweiseitige Tests. Denn dann ist man unvoreingenommen und ganz neutral bezüglich irgendwelcher Vorurteile gegen mögliche Zusammenhänge in den Daten. Auch in den gängigen Statistikprogrammen werden standardmäßig zweiseitige Tests verwendet.
Natürlich kann man trotzdem einen einseitigen Test verwenden – in Klausuren wird das auch gerne mal verlangt – aber in der Praxis muss man die Wahl dann schon gut begründen können.
Der absolute Wert des Parameters sagt wenig aus
Es ist noch wichtig zu erwähnen, dass man die „Wichtigkeit“ eines Parameters nicht an seinem absoluten Wert ablesen kann. Wenn man also einen Koeffizienten von \(b = 0.5158\) hat, weiß man noch lange nicht ob er wichtig, d.h. signifikant oder nicht ist.
Es kommt nämlich darauf an, auf welcher Skala die Einflussgröße lebt. Dazu ein kurzes Beispiel: Wir messen die Größe einer Person, und ihr Gewicht. Auf der linken Grafik zeigen wir das Ergebnis, wenn wir die Größe in Zentimetern messen: \(y = -7.26 + 0.5158 \cdot x\). Der Steigungsparameter ist hier also \(b=0.5158\). Auf der rechten Grafik zeigen wir genau dieselben Daten, aber das ist das Ergebnis, falls wir die Körpergröße in Metern gemessen hätten. Das Ergebnis wäre dann \(y = -7.26 + 51.58 \cdot x\).
Das ist im Prinzip dasselbe Regressionsmodell, nur mit unterschiedlich skalierten Einflussgrößen. Du kannst gerne vergewissern, dass für deine persönliche Größe auch in beiden Modellen dasselbe Gewicht vorhergesagt wird. Bei einer Größe von 170cm wäre es z.B. für das Ergebnis \(y\) egal, ob man (im linken Modell) \(0.5158 \cdot 170\), oder (im rechten Modell) \(51.58 \cdot 1.70\) rechnet.
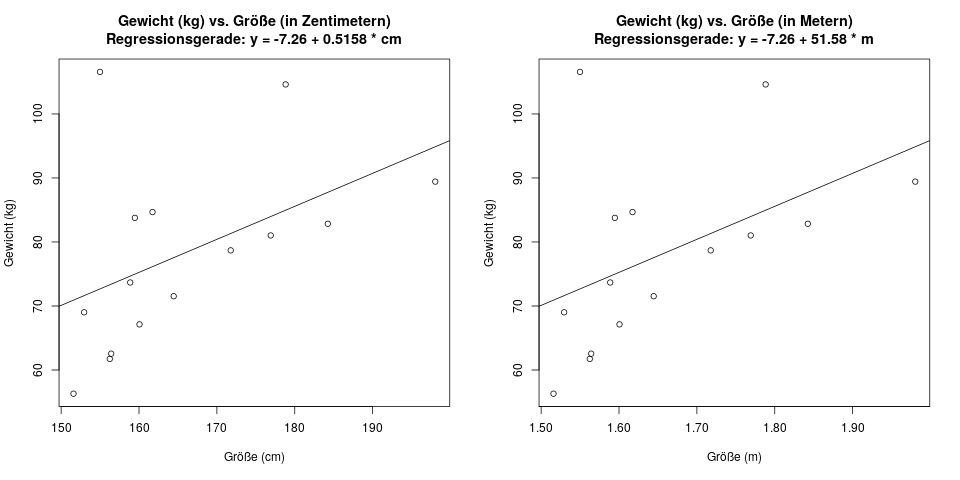
Das bedeutet, dass man für eine Aussage zur Wichtigkeit eines Parameters immer den Parameterschätzer zusammen mit dem p-Wert betrachten muss.
Beispielaufgabe
Die folgende Aufgabe soll dabei helfen, ein Gespür dafür zu bekommen, wie ein plausibles Regressionsmodell aussieht.
Ein Marktforschungsunternehmen möchte mit einem Regressionsmodell die Verkaufszahlen für Zahnpasta in einer Ladenkette vorhersagen. Als Einflussgrößen hat es dafür den Preis einer Tube Zahnpasta, und die Außentemperatur in °C zur Verfügung.
Das Unternehmen sammelt also über einen Monat hinweg Daten, und rechnet dann eine Regression.
Die Regressionsgerade für diese Studie lautet: \(y = a + b_1 * x_1 + b_2 * x_2\), wobei \(x_1\) der Preis einer Tube in Euro ist, und \(x_2\) die Außentemperatur in °C.
Wir haben schon eine Vorahnung, wie der Einfluss auf die Verkaufszahlen aussehen wird:
- Wir erwarten, dass der Preis einer Tube \(x_1\) einen negativen Einfluss auf die Verkaufszahlen hat, d.h. wenn der Preis größer wird, dann müssten weniger Tuben verkauft werden, d.h. die Zielgröße \(y\) wird kleiner.
- Für die Außentemperatur \(x_2\) vermuten wir keinen Einfluss. Bei einer Eisdiele wäre das anders, denn bei mehr Sonne wird normalerweise auch mehr Eis verkauft. Hier gehen wir aber mal davon aus, dass Zahnpasta zu jedem Wetter gleich gut verkauft wird.
Welches der folgenden Ergebnisse ist auf diese zwei Vermutungen hin das plausibelste?
a)
| Parameter | Schätzer | p-Wert |
|---|---|---|
| \(a\) | 1543.22 | 0.013 |
| \(b_1\) | 0.012 | 0.042 |
| \(b_2\) | 2.042 | 0.013 |
b)
| Parameter | Schätzer | p-Wert |
|---|---|---|
| \(a\) | 1543.22 | 0.013 |
| \(b_1\) | -934.02 | 0.017 |
| \(b_2\) | 37.02 | 0.006 |
c)
| Parameter | Schätzer | p-Wert |
|---|---|---|
| \(a\) | 1543.22 | 0.013 |
| \(b_1\) | -952.21 | 0.003 |
| \(b_2\) | -13.23 | 0.493 |
d)
| Parameter | Schätzer | p-Wert |
|---|---|---|
| \(a\) | 1543.22 | 0.013 |
| \(b_1\) | 12.23 | 0.342 |
| \(b_2\) | 63.42 | 0.255 |