
Balkendiagramme sind die einfachste Variante, um diskrete Daten zu visualisieren. In einem Balkendiagramm wird für jede mögliche Ausprägung des untersuchten Merkmals ein Balken gezeichnet. Dessen Höhe ist proportional zur jeweiligen Häufigkeit des Merkmals. Es ist für die Grafik selbst egal, ob hier relative oder absolute Häufigkeiten verwendet werden, es ändert sich nur die Skala auf der \(y\)-Achse.
Kurz am Rande: Das Balkendiagramm heißt genaugenommen Säulendiagramm, da die Daten als vertikale Säule dargestellt werden. Ein Balkendiagramm hingegen hätte man, wenn die komplette Grafik um 90 Grad nach rechts gedreht wird. Das Erstellen dieses Diagramms geht aber genauso wie beim Säulendiagramm, und ich finde den Begriff „Balkendiagramm“ einfach schöner 🙂
 Im eBook-Shop gibt es Klausuraufgaben zu diesem Thema!
Im eBook-Shop gibt es Klausuraufgaben zu diesem Thema!Beispielaufgabe
Wir benutzen die Daten aus dem Artikel zu Häufigkeitstabellen:
| Semester \(i\) | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| \(h_i\) | 20 | 4 | 13 | 9 | 21 | 5 | 8 |
| \(f_i\) | 0.25 | 0.05 | 0.1625 | 0.1125 | 0.2625 | 0.0625 | 0.1 |
| \(F_i\) | 0.25 | 0.3 | 0.4625 | 0.575 | 0.8475 | 0.9 | 1 |
Damit zeichnen wir nun ein Balkendiagramm für die absolute (die Zeile \(h_i\)) und relative (die Zeile \(f_i\)) Häufigkeit für jedes Semester.
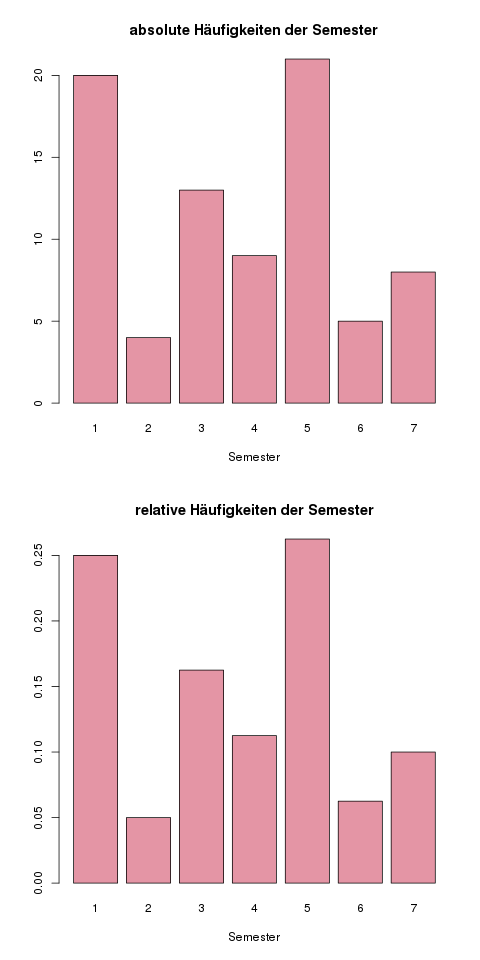
Hier sieht man nun, dass sich nur die Skalierung der \(y\)-Achse ändert; die (relativen) Höhen der Balken bleiben gleich.
Das sind Säulen und keine Balken
Oh, stimmt. Ich habe oben einen erklärenden Absatz ergänzt.
Danke für den Hinweis 🙂