
 Im eBook-Shop gibt es Klausuraufgaben zu diesem Thema!
Im eBook-Shop gibt es Klausuraufgaben zu diesem Thema!Wann verwendet man einen Einstichproben-t-Test?
Der t-Test ist wohl der bekannteste und am häufigsten verwendete Hypothesentest. Er kommt immer dann zum Einsatz, wenn man Hypothesen prüfen möchte, die Aussagen über einen Mittelwert treffen. Zwei Beispiele:
- „Die Bahn kommt an diesem Bahnhof im Mittel mindestens 3 Minuten zu spät.“
- „Der durchschnittliche Blutdruck von Rauchern ist höher als der von Nichtrauchern“
Im zweiten Beispiel, das mit dem Blutdruck, haben wir zwei Gruppen, müssen also zwei Stichproben erheben: Eine von einigen Rauchern, und eine zweite von einigen Nichtrauchern. Das wäre ein Zweistichproben-t-Test, dieser Fall wird im nächsten Artikel behandelt.
Der einfachere Spezialfall unter den t-Tests ist nun der Einstichproben-t-Test. Er wird immer dann verwendet, wenn man nur eine Stichprobe (d.h. keine Gruppen) hat, also nur einen einzelnen Mittelwert testen möchte – so wie es im ersten Beispiel, mit der Verspätung der Bahn, der Fall war.
Dieser Test heißt t-Test, weil die Prüfgröße eine t-Verteilung hat.
Einführende Artikel
Zum Einstieg sollte man sich zu Beginn die folgenden beiden Artikel durchlesen:
In ihnen beschreibe ich ganz allgemein die Schritte, mit denen man einen Hypothesentest durchführt. Dadurch werden die einzelnen Teile in diesem Artikel verständlicher.
Außerdem macht es Sinn, den Artikel zum Binomialtest zu lesen, da ich dort noch etwas ausführlicher beschrieben habe, wie man die allgemeinen Prinzipien auf einen speziellen Test anwendet. Falls hier etwas nur kurz beschrieben wird, dann ist es im Artikel zum BInomialtest evtl. ausführlicher verständlicher erklärt worden.
1. Hypothesen aufstellen
Beim t-Test gibt es, genau wie beim Binomialtest, drei verschiedene Möglichkeiten, seine Hypothesen zu formulieren. Welche Variante man verwenden muss, hängt von der Fragestellung ab, die man untersucht. Dazu drei Beispiele:
- Ein misstrauischer Oktoberfestbesucher möchte nachweisen, dass in den Maßkrügen im Durchschnitt weniger als 1 Liter Bier eingeschenkt wurde. Die Alternativhypothese muss also sagen, dass der MIttelwert kleiner als 1000ml ist. Insgesamt also:
- \(H_0: \mu \geq 1000ml\)
- \(H_1: \mu < 1000ml\)
- Ein Dorf behauptet, dass seine Bewohner im Mittel über 100 Jahre alt werden. Um das nachzuweisen, muss der Fall „erreichtes Lebensalter (\(\mu\)) ist über 100 Jahre“ in die Alternativhypothese \(H_1\) (warum das so ist, wird in diesem Artikel beschrieben). Die Hypothesen lauten also:
- \(H_0: \mu \leq 100\)
- \(H_1: \mu > 100\)
- In einer Fabrik werden Frühstücksmüslis in Packungen zu 750g abgefüllt. Die Qualitätssicherung überprüft, dass in eine Packung im Durchschnitt weder zu wenig noch zu viel Müsli gefüllt wird. Die Nullhypothese bezeichnet also den Normalzustand, \(\mu = 750g\), und die Alternativhypothese geht nun in beide Richtungen – insgesamt also:
- \(H_0: \mu = 750g\)
- \(H_1: \mu \neq 750g\)
Im restlichen Artikel verwende ich das dritte Beispiel mit den Müslipackungen, und zeige am Ende noch kurz, welche Veränderungen man in den anderen beiden Fällen vornehmen müsste.
2. Test wählen
Um die Abfolge der 8 Schritte nicht zu verändern, die wir in den beiden einführenden Artikeln aufgestellt haben (erster und zweiter Artikel), nehme ich hier den 2. Schritt auch mit auf. Es ist natürlich schon klar, dass wir einen Einstichproben-t-Test verwenden werden.
3. Signifikanzniveau festlegen
Wie in den vorherigen Artikeln schon beschrieben, legt das Signifikanzniveau die Wahrscheinlichkeit fest, mit der man einen bestimmten Fehler macht, nämlich die fälschliche Entscheidung dass die Alternativhypothese gilt, obwohl in Wirklichkeit die Nullhypothese wahr ist.
Allgemeiner Konsens ist hier ein Wert von 5%, also \(\alpha = 0.05\). In besonders kritischen Fragestellungen, z.B. solchen, die die menschliche Gesundheit betreffen, muß das Signifikanzniveau oft niedriger gewählt werden, der Test wird dann konservativer. Hier wählt man z.B. \(\alpha = 0.01\).
Für unsere Beispielaufgabe nehmen wir das übliche Signifikanzniveau von \(\alpha = 0.05\).
4. Daten sammeln
In einer Klausur oder Übung gibt es die Daten natürlich meist schon. Wenn man sie aber selber sammelt, müssen die Daten für einen Einstichproben-t-Test eigentlich nur eine lange Liste von Dezimalzahlen sein. Wir fassen diese Daten dann im 5. Schritt zusammen in zwei Werte, in unserem Beispiel erstens den Mittelwert der Daten, \(\bar{x}\), und zweitens die Standardabweichung, \(s\). Diese beiden Werte brauchen wir für den Einstichproben-t-Test.
In unserem Beispiel betrachten wir zehn Müslipackungen und wiegen ihren exakten Inhalt ab. Wir erhalten die folgenden Messwerte:
| Packung \(x_i\) | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Inhalt | 749g | 755g | 757g | 751g | 743g | 750g | 752g | 750g | 757g | 757g |
5. Prüfgröße berechnen
Die Prüfgröße beim t-Test heißt \(T\), und setzt sich aus vier Zahlen zusammen:
- Der Mittelwert der gemessenen Werte, \(\bar{x}\). Der Mittelwert der zehn Packungen bei uns ist 752.1g.
- Die Standardabweichung der gemessenen Werte, \(s\). Hier ist die Standardabweichung 4.508. Eine ausführliche Erklärung dazu findest du in diesem Artikel.
- Der „tatsächliche“ bzw. unterstellte Mittelwert \(\mu_0\). Da wir von einem Packungsinhalt von 750g ausgehen, ist bei uns \(\mu_0 = 750g\)
- Wie groß die Stichprobe ist. Je mehr Daten man erhoben hat, desto genauer ist nämlich die Schätzung für den Mittelwert. Wir haben \(n=10\) Beobachtungen. In der Formel brauchen wir gleich die Wurzel aus dieser Zahl
Die Formel für die Berechnung der Prüfgröße lautet nun
\[ T = \sqrt{n} \cdot \frac{\bar{x} \, – \, \mu_0}{s} \]
Bei uns setzen wir also ein:
\[ T = \sqrt{10} \cdot \frac{752.1 \, – \, 750}{4.508} = 1.473 \]
Unsere Prüfgröße ist also \(T = 1.473\).
6. Verteilung der Prüfgröße bestimmen
Falls in Wirklichkeit tatsächlich durchschnittlich 750g in einer Müslipackung sind, dann ist der Mittelwert t-verteilt mit \(n-1\) Freiheitsgraden. Da unsere Prüfgröße \(T\) schon standardisiert ist, ist es ab jetzt egal, welchen Mittelwert \(\mu_0\) wir unterstellen, und welche Standardabweichung die Daten haben.
Die Bezeichnung „Freiheitsgrade“ ist ein wenig kompliziert, und ich bin der Meinung, dass man das Konzept nicht unbedingt verstehen muss – man kann das Wort ohne Probleme einfach so akzeptieren. Man muss sich nur merken, dass man bei einer Stichprobe der Größe \(n\) eben die t-Verteilung mit \(n-1\) Freiheitsgraden verwenden muss.
Bei unserem Beispiel ist \(n=10\), wir verwenden also die t-Verteilung mit \(n-1=9\) Freiheitsgraden:
\[ T \sim t(9) \]
7. Kritischen Bereich (oder p-Wert) berechnen
Den kritischen Bereich erhalten wir mit Hilfe einer Tabelle der t-Verteilung, die in einem eigenen Artikel erklärt wird. Wir suchen einen kritischen Bereich, in dem unser Ergebnis (d.h. die Prüfgröße \(T\)) nur zu 5% (das ist das SIgnifikanzniveau \(\alpha\)) fallen würde, falls die Nullhypothese gilt. Da wir hier einen zweiseitigen Test verwenden, teilen wir diese 5% auf in jeweils 2.5% links und 2.5% rechts. Man kann sich das so vorstellen, dass sowohl besonders kleine, als auch besonders große Werte von \(\bar{x}\) (und somit auch von \(T\)) gegen die Nullhypothese sprechen.
Mir hat es zum Verständnis immer geholfen, ein Diagramm zu zeichnen, um zu verstehen welche Werte wir suchen.
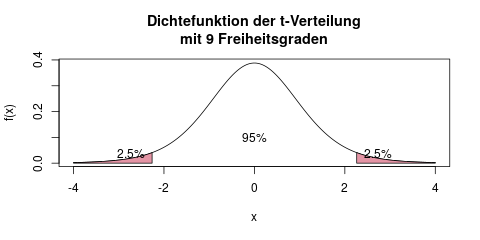 Wir suchen nun die beiden Grenzen, die den kritischen Bereich einrahmen. An der Grafik erkennt man schon, dass sie ein bisschen über der 2 liegen, vielleicht bei -2,3 und +2,3.
Wir suchen nun die beiden Grenzen, die den kritischen Bereich einrahmen. An der Grafik erkennt man schon, dass sie ein bisschen über der 2 liegen, vielleicht bei -2,3 und +2,3.
Die genauen Werte erhalten wir aus der Tabelle der t-Verteilung (im Artikel zur t-Verteilung ist auch genauer erklärt, wie man das macht). Die rechte Schranke ist das 97,5%-Quantil der t-Verteilung mit 9 Freiheitsgraden, und aus der Tabelle lesen wir den Wert 2,262 ab. Prüfe das am besten selbst nach, es ist für eine Klausur unerlässlich, das schnell und sicher zu können.
Die linke Schranke ist -2,262, denn da die t-Verteilung symmetrisch um 0 ist, können wir einfach den negativen Wert von der rechten Schranke (2,262) nehmen. Der kritische Bereich ist also der in der Grafik rot eingefärbte Bereich, es ist der Bereich außerhalb der beiden Schranken.
8. Testentscheidung treffen
Insgesamt wissen wir nun: Wenn unsere Prüfgröße \(T\) innerhalb des Bereichs [-2,262, 2,262] liegt, dann spricht das für die Nullhypothese. Liegt \(T\) aber außerhalb (also im kritischen, roten Bereich), dann können wir die Nullhypothese ablehnen, und unsere Testentscheidung fällt zugunsten der Alternativhypothese \(H_1\) aus.
In Schritt 5 haben wir \(T = 1.473\) ausgerechnet. Die Prüfgröße liegt also nicht im kritischen Bereich. Es ist also „alles in Ordnung“: Wir können weiterhin von der Nullhypothese ausgehen, und haben keinen Anlass dafür den Abfüllmechanismus in der Müslifabrik zu reparieren.
Änderungen bei den zwei anderen Beispielen
Im Beispiel dieses Artikels haben wir einen zweiseitigen t-Test durchgeführt. Falls man einen einseitigen t-Test rechnen möchte, so wie in den anderen beiden Beispielen die oben schon erwähnt wurden, dann ist der kritische Bereich nur auf einer Seite der möglichen Werte für die Prüfgröße \(T\). Im ersten Beispiel, das mit dem misstrauischen Oktoberfestbesucher, ist der kritische Bereich z.B. nur durch zu wenig befüllte Maßkrüge, also durch kleine Werte für die Prüfgröße gegeben. Der kritische Bereich dort wird also das linke Ende der t-Verteilung sein, und zwar die linken 5% (statt der 2,5%, die beim zweiseitigen Test verwendet wurden). Die Schranke, die den kritischen Bereich abgrenzt, ist das 5%-Quantil der t-Verteilung:
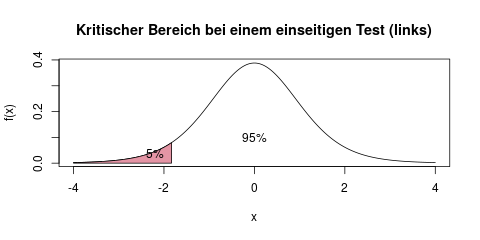
Wenn also die Prüfgröße \(T\) kleiner als ca. 1,9 ist (der genaue Wert hängt wieder von der Stichprobengröße, also der Anzahl der Freiheitsgrade ab), dann lehnen wir die Nullhypothese in diesem Fall ab.
Falls der Test allerdings einseitig nach rechts testet, z.B. beim 3. Beispiel (die Dorfbewohnern, die behaupten dass sie im Mittel über 100 Jahre werden), dann ist der kritische Bereich das rechte Ende der t-Verteilung. Hier bräuchten wir also das 95%-Quantil als Schranke zum kritischen Bereich:

Den Freiheitsgrad kann man sich als Anzahl an „überflüssigen“ (oder mehrfachen) Beobachtungen der Messgröße vorstellen. Um überhaupt eine Messgröße vorliegen zu haben, brauche ich zumindest eine Beobachtung. Alle weiteren Beobachtungen (derselben Größe) dienen dann „nur“ mehr der Genauigkeitssteigerung.
Sehr schöner Gedanke, auf diese Art hab ich mir Freiheitsgrade noch nicht vorgestellt. Aber das macht Sinn!
Danke, Sie können diesen Gedanken gerne in ihre Beschreibung übernehmen, falls Sie möchten („überzählig“ statt „überflüssig“ wäre vlt das geeignetere Adjektiv). Ihre Seiten sind hervorragend. Vielen Dank für die Freistellung, sind mir gerade eine große Hilfe.
Hi Alex,
auch von mir zunächst vielen Dank für deine genialen Erklärungen! Ich wünschte, du wärst mein Statistik-Professor… 🙂
Nun zu meiner Frage:
Hier lesen wir in Schritt 7 den Wert für n – 1 = 9 Freiheitsgrade in der Tabelle ab, beim Zweistichproben-t-Test hingegen den Wert für n Freiheitsgrade. Lässt sich das verallgemeinern oder entscheidet ein anderes Kriterium als die Art des Tests darüber, welchen Freiheitsgrad man in der Tabelle ablesen muss? Vielen Dank!
Hi,
beim Zweistichprobentest haben wir ja zwei Stichproben. Die eine hat \(n_x\) Personen, die andere hat \(n_y\) (es gibt also gar kein \(n\)). Im Artikel dort sind es 6 und 8 Personen. Beim Testen brauchst du als Anzahl der Freiheitsgrade dann \(n_x+n_y-2\), also in dem Fall df=12.
Hilft dir das weiter? Ich weiß nicht genau ob ich die Frage richtig verstanden habe 🙂
VG
Alex
Wow, vielen Dank für die schnelle Antwort! Ja, jetzt ist es klar. Ich habe die relevante Stelle im Artikel wohl versehentlich überlesen, sorry… 😉